3. Xarray#
1. Xarray#
1.1: Introduction#
Xarray builds off of Pandas and is designed to handle higher dimensional data and extends NumPy capabilities by allowing labels to dimensions. It has extensive integration into other packages and is extensivley used when dealing with complex IOT datasets, or those involving climate science. There are two major classes (data structures) in Xarray, DataArray and Dataset.
DataArray - Multi-dimensional data container, like a labeled Numpy Array
Dataset - A collection of DataArray objects, similar to Pandas DataFrame, but for multi-dimensional data.
Why Should Chemistry & IoT Data Use Xarray?
Feature |
Benefit for Chemistry & IoT Data |
|---|---|
Labeled Dimensions |
Easily track wavelength, time, temperature, sensor IDs. |
Multi-Dimensional |
Store spectra, reaction kinetics, air quality sensor data in one dataset. |
Lazy Loading |
Handle large environmental datasets efficiently. |
Dask Integration |
Scale to **big data (IoT sensor streams, satellite data). |
1.2: Xarray & Other Libraries#
Xarray is widely used in
Climate Science
Remote Sensing
Oceanography and Meteorology
Multidimensional Sensor Data (IoT, Machine Learning)
Xarray extends Pandas and NumPy, but is also a dependency many other libraries depend on.
Library |
Xarray’s Relationship |
|---|---|
Pandas |
Xarray extends Pandas to higher dimensions (3D+ data). |
NumPy |
Xarray uses NumPy arrays under the hood. |
NetCDF |
Xarray natively reads/writes NetCDF files (widely used in climate science). |
Dask |
Xarray supports parallel computing with Dask for large datasets. |
Bottleneck |
Xarray automatically optimizes performance using Bottleneck for fast reductions (mean, sum, min..) and handling NaNs. |
SciPy |
Xarray integrates with SciPy for interpolation and optimization. |
Install xarray#
Open up your terminal and activate your virtual environment, and then install xarray using miniconda.
conda install -c conda-forge xarray
xarray is typically importated as xr
import xray as xr
2. Xarray I/O Functions#
2.1 Files Pandas can read#
Xarray does not duplicate Pandas I/O functions for formats that DataFrames can already handle efficiently (e.g., CSV, Excel, JSON). For files of these formats the typical workflow is”
Use Pandas to read general-purpose data formats (CSV, Excel, JSON).
Convert the Pandas DataFrame into an Xarray object (
DatasetorDataArray).
Xarray provides specialized I/O functions for multidimensional data (NetCDF, Zarr, GeoTIFF).
2.2 Multidimensional files#
The following table provides read and write functions within xarray. Note the latter two convert xarray to other pythonic structures.
Function |
Reads/Writes |
File Format |
Description |
|---|---|---|---|
|
Read |
NetCDF |
Open a NetCDF file as an |
|
Read |
NetCDF |
Open a single NetCDF variable as an |
|
Read |
NetCDF |
Load NetCDF into memory instead of lazy loading. |
|
Read |
NetCDF |
Load a single NetCDF variable into memory. |
|
Read |
Zarr |
Open a Zarr file as an Xarray Dataset. |
|
Read |
Zarr |
Load a Zarr file into memory. |
|
Read |
GeoTIFF |
Open a GeoTIFF file for spatial analysis. |
|
Read |
NetCDF |
Open multiple NetCDF files as a single dataset (lazy loading). |
|
Write |
NetCDF |
Save an Xarray |
|
Write |
NetCDF |
Save an Xarray |
|
Write |
Zarr |
Save an Xarray |
|
Write |
CSV |
Save a dataset as a CSV file (lossy conversion). |
|
Convert |
Pandas DataFrame |
Convert an |
|
Convert |
Dictionary |
Convert an |
3. Xarray Functions#
Xarray Functions#
Function |
Description |
|---|---|
|
Open a NetCDF file as an Xarray |
|
Open a single NetCDF variable as an |
|
Create a new multi-dimensional dataset. |
|
Create a single variable with labeled axes. |
|
Concatenate Xarray objects along a new dimension. |
|
Merge multiple datasets into one. |
|
Combine datasets by aligning their coordinates. |
|
Align two Xarray objects to a common set of coordinates. |
|
Apply a function to Xarray objects, supporting parallelization. |
|
Perform conditional selection like NumPy’s |
|
Expand dimensions to make two datasets compatible for operations. |
|
Compute the correlation coefficient along a specified dimension. |
|
Load a dataset into memory (useful for NetCDF files). |
|
Save multiple datasets into separate NetCDF files. |
4. DataArray#
4.1 Attributes#
Attribute |
Description |
|---|---|
|
Returns the raw NumPy array backing the |
|
Tuple of dimension names (e.g., |
|
Shape of the |
|
Number of dimensions in the |
|
Total number of elements in the |
|
Dictionary of coordinate labels (e.g., |
|
Dictionary of metadata attributes (e.g., |
|
Name of the |
|
Data type of the |
|
Total memory usage in bytes. |
|
Dictionary mapping dimension names to sizes. |
|
Dictionary of Pandas |
|
If using Dask, shows chunk sizes for parallel computation. |
4.2 Methods#
Method |
Description |
|---|---|
|
Extract the underlying NumPy array. |
|
Get the names of dimensions. |
|
Get coordinate labels. |
|
Transpose dimensions. |
|
Add a new dimension. |
|
Remove singleton dimensions. |
|
Generate quick visualizations. |
|
Apply rolling-window operations. |
5. Dataset#
5.1 Attributes#
Attribute |
Description |
|---|---|
|
Dictionary of variables ( |
|
Dictionary of dimension names and their sizes. |
|
Dictionary of coordinate labels for each dimension. |
|
Dictionary of metadata attributes (e.g., |
|
Dictionary of dimension names mapped to their sizes. |
|
Dictionary of Pandas |
|
Dictionary of all variables (both data and coordinates). |
|
If using Dask, shows chunk sizes for parallel computation. |
|
Total memory usage in bytes. |
|
Data type of the stored variables. |
|
Shape of the dataset as a tuple (not commonly used). |
|
Dictionary of encoding options (useful for NetCDF/Zarr storage). |
5.2 Methods#
Method |
Description |
|---|---|
|
Select data by index (position-based). |
|
Select data by coordinate label. |
|
Drop variables from a dataset. |
|
Rename variables or dimensions. |
|
Compute the mean along a given dimension. |
|
Compute the sum along a given dimension. |
|
Group data by a coordinate value. |
|
Resample time-series data. |
|
Apply rolling window operations. |
|
Compute the numerical derivative. |
|
Compute the numerical integral. |
6. Xarray Activity#
In this activity we will generate a simulated kinetics plot of the spectra of a hypothetical molecule that follows a Boltzmann distrution and save it as a csv file. Then we will load the csv file into an xarray DataArray and explore it.
6.1 Create spectra simulation#
import os
import numpy as np
import xarray as xr
import pandas as pd
import matplotlib.pyplot as plt
# Define base directory and file path
base_data_dir = os.path.expanduser("~/data")
spectra_dir = os.path.join(base_data_dir, "spectra")
os.makedirs(spectra_dir, exist_ok=True) # Ensure directory exists
# Define the file path for saving
spec2_vis_csv_spectrapath = os.path.join(spectra_dir, "spec2_vis.csv")
# Define wavelength and time ranges
wavelengths = np.linspace(350, 700, 100) # 100 wavelength points
times = np.linspace(0, 300, 30) # 30 time points
# Simulate Absorbance Spectrum with a Boltzmann-like Shape Across Wavelengths
def generate_spectrum(wavelengths, peak_wavelength=525, width=50, max_absorbance=1.0):
"""Create a Gaussian peak across the wavelength range."""
return max_absorbance * np.exp(-((wavelengths - peak_wavelength) ** 2) / (2 * width ** 2))
base_spectrum = generate_spectrum(wavelengths)
# Use exponential decay for time behavior
def kinetic_decay(time, t_half=100):
"""Exponential decay function"""
return np.exp(-time / t_half) # Corrected to true exponential decay
# Create a 2D Absorbance Array for (Wavelength, Time)
absorbance = np.outer(base_spectrum, kinetic_decay(times))
# Convert to Xarray Dataset
ds = xr.Dataset(
data_vars={"absorbance": (["wavelength", "time"], absorbance)},
coords={"wavelength": wavelengths, "time": times}
)
# **Use the correct colormap: "Red-Yellow-Green" (Reversed)**
cmap = plt.get_cmap("RdYlGn_r") # Green → Yellow → Red
norm = plt.Normalize(vmin=times.min(), vmax=times.max())
# **Create figure**
fig, ax = plt.subplots(figsize=(10, 6))
# **Plot the evolving spectra using traffic light colors**
for i, time in enumerate(times):
ax.plot(
wavelengths,
ds.absorbance.sel(time=time),
color=cmap(norm(time)),
label=f"{int(time)} min" if int(time) % 100 == 0 else None
)
# **Labels and title**
ax.set_xlabel("Wavelength (nm)")
ax.set_ylabel("Absorbance")
ax.set_title("Simulated Kinetic Spectral Evolution (Traffic Light Gradient)")
ax.grid(True)
# **Add a colorbar to show the time evolution properly**
sm = plt.cm.ScalarMappable(norm=norm, cmap=cmap)
sm.set_array([])
cbar = plt.colorbar(sm, ax=ax, label="Time (min)")
# **Show the plot**
plt.show()
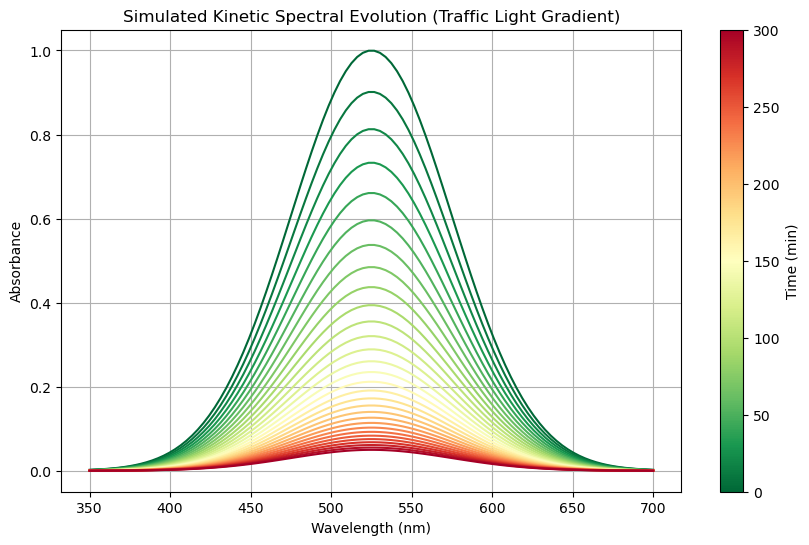
6.2 Load CSV into Xarray#
The first step is to load the CSV into a Dataset. This can be a challenge and will often require you to look at the csv file to see how it is structured
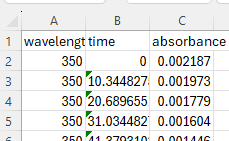
Here you can see that the first row (index 0) is labels of the variable type string. The following code will read the csv into a pandas dataframe, manipulate it so we can convert it to a dataframe and then create the dataframe.
** Line-by-line explanation of code**
Importing Required Libraries
import pandas as pd
import xarray as xr
import os
pandas(pd): Used for reading and manipulating the CSV file as a DataFrame.xarray(xr): Used to create and structure the data into a labeledxarray.Dataset.os: Used to construct file paths dynamically and ensure necessary directories exist.
Defining the File Path
# Define base directory and file path
base_data_dir = os.path.expanduser("~/data")
spectra_dir = os.path.join(base_data_dir, "spectra")
os.makedirs(spectra_dir, exist_ok=True) # Ensure directory exists
# Define the file path
spec2_vis_csv_spectrapath = os.path.join(spectra_dir, "spec2_vis.csv")
os.path.expanduser("~/data"): Expands~(home directory) to its full path.os.path.join(base_data_dir, "spectra"): Constructs the full path to thespectrafolder.os.makedirs(spectra_dir, exist_ok=True): Creates the directory if it doesn’t exist.spec2_vis_csv_spectrapath: Stores the full path of the CSV file.
Loading the CSV File into Pandas*
# Define file path
file_path = spec2_vis_csv_spectrapath # Replace with your actual file path
# Load CSV with the first row as the header
df_clean = pd.read_csv(file_path, header=0)
Reads the CSV file, assuming the first row (
header=0) contains column names.Stores it in a Pandas DataFrame (
df_clean).
Debugging - Inspecting the Data
# Display the first few rows and column names for debugging
print(df_clean.head())
print(df_clean.columns)
Helps confirm whether the data is read correctly.
Sometimes, the first row is mistakenly treated as data instead of headers.
Renaming Columns for Consistency
# Rename columns to avoid confusion
df_clean.columns = ['Wavelength', 'Time', 'Absorbance']
Explicitly renames the columns to prevent confusion.
Ensures consistent naming and avoids issues with column access.
Converting Data to Numeric Format
# Convert 'Wavelength' and 'Time' columns to numeric values
df_clean['Wavelength'] = pd.to_numeric(df_clean['Wavelength'], errors='coerce')
df_clean['Time'] = pd.to_numeric(df_clean['Time'], errors='coerce')
Converts
WavelengthandTimecolumns to numeric types.errors='coerce':Converts non-numeric values (e.g., missing or incorrect data) to
NaN.
Removing Invalid Data
# Drop rows with NaN values in 'Wavelength' or 'Time' columns
df_clean.dropna(subset=['Wavelength', 'Time'], inplace=True)
Ensures the dataset contains only valid numeric values.
Extracting Unique Time Values
# Extract unique time values
time_values = df_clean['Time'].unique()
Gets unique time values from the
Timecolumn.Needed later for defining
xarray.Datasetcoordinates.
Reshaping the Data for Xarray
# Pivot the DataFrame to have 'Wavelength' as index and 'Time' as columns
df_pivot = df_clean.pivot(index='Wavelength', columns='Time', values='Absorbance')
Transforms DataFrame:
Rows become wavelengths.
Columns become time values.
Cells store absorbance data.
Why? This is necessary to create a structured
xarray.Dataset.
Creating the Xarray Dataset
# Convert the pivoted DataFrame to an xarray Dataset
ds_final = xr.Dataset(
data_vars={'absorbance': (['wavelength', 'time'], df_pivot.values)},
coords={'wavelength': df_pivot.index.values, 'time': df_pivot.columns.values}
)
data_vars:Defines
'absorbance'as a 2D array with dimensions (wavelength,time).
coords:'wavelength'and'time'are used as coordinate labels.
This makes it easy to analyze, filter, and visualize the data.
Printing the Final Dataset
# Display dataset summary
print(ds_final)
Prints the final
xarray.Dataset, confirming it has the expected dimensions.
import pandas as pd
import xarray as xr
import os
# Define base directory and file path
base_data_dir = os.path.expanduser("~/data")
spectra_dir = os.path.join(base_data_dir, "spectra")
os.makedirs(spectra_dir, exist_ok=True) # Ensure directory exists
# Define the file path
spec2_vis_csv_spectrapath = os.path.join(spectra_dir, "spec2_vis.csv")
# Define file path
file_path = spec2_vis_csv_spectrapath # Replace with your actual file path
# Load CSV with the first row as the header
df_clean = pd.read_csv(file_path, header=0)
# Display the first few rows and column names for debugging
print(df_clean.head())
print(df_clean.columns)
# Rename columns to avoid confusion
df_clean.columns = ['Wavelength', 'Time', 'Absorbance']
# Convert 'Wavelength' and 'Time' columns to numeric values
df_clean['Wavelength'] = pd.to_numeric(df_clean['Wavelength'], errors='coerce')
df_clean['Time'] = pd.to_numeric(df_clean['Time'], errors='coerce')
# Drop rows with NaN values in 'Wavelength' or 'Time' columns
df_clean.dropna(subset=['Wavelength', 'Time'], inplace=True)
# Extract unique time values
time_values = df_clean['Time'].unique()
# Pivot the DataFrame to have 'Wavelength' as index and 'Time' as columns
df_pivot = df_clean.pivot(index='Wavelength', columns='Time', values='Absorbance')
# Convert the pivoted DataFrame to an xarray Dataset
ds_final = xr.Dataset(
data_vars={'absorbance': (['wavelength', 'time'], df_pivot.values)},
coords={'wavelength': df_pivot.index.values, 'time': df_pivot.columns.values}
)
# Display dataset summary
print(ds_final)
wavelength time absorbance
0 350.0 0.000000 0.002187
1 350.0 10.344828 0.001973
2 350.0 20.689655 0.001779
3 350.0 31.034483 0.001604
4 350.0 41.379310 0.001446
Index(['wavelength', 'time', 'absorbance'], dtype='object')
<xarray.Dataset> Size: 25kB
Dimensions: (wavelength: 100, time: 30)
Coordinates:
* wavelength (wavelength) float64 800B 350.0 353.5 357.1 ... 696.5 700.0
* time (time) float64 240B 0.0 10.34 20.69 31.03 ... 279.3 289.7 300.0
Data variables:
absorbance (wavelength, time) float64 24kB 0.002187 0.001973 ... 0.0001089
6.3 Save Xarray Dataset as NetCDF file#
base_data_dir = os.path.expanduser("~/data")
spectra_dir = os.path.join(base_data_dir, "spectra")
os.makedirs(spectra_dir, exist_ok=True) # Ensure directory exists
# Define the file path
spec2_nc_spectrapath = os.path.join(spectra_dir, "spec2_vis.nc")
ds_final.to_netcdf(spec2_nc_spectrapath)
# Confirm that the file has been saved
if os.path.isfile(spec2_nc_spectrapath):
print(f"Dataset successfully saved to: {spec2_nc_spectrapath}")
else:
print("Failed to save the dataset.")
Dataset successfully saved to: /home/rebelford/data/spectra/spec2_vis.nc
6.4 Loading NetCDF file to Dataset#
import xarray as xr
# Define the path to your NetCDF file
file_path = spec2_nc_spectrapath # Ensure this variable contains the correct path to 'cpec2_vis.nc'
# Open the NetCDF file and assign it to a new Dataset
new_ds = xr.open_dataset(file_path)
# Display the contents of the new Dataset
print(new_ds)
<xarray.Dataset> Size: 25kB
Dimensions: (wavelength: 100, time: 30)
Coordinates:
* wavelength (wavelength) float64 800B 350.0 353.5 357.1 ... 696.5 700.0
* time (time) float64 240B 0.0 10.34 20.69 31.03 ... 279.3 289.7 300.0
Data variables:
absorbance (wavelength, time) float64 24kB ...
6.5 Exploring the Data#
We will first look at the range of our variables.
Find Range of Variables#
# Range of absorbance
absorbance_min = new_ds['absorbance'].min().item()
absorbance_max = new_ds['absorbance'].max().item()
# Range of wavelength
wavelength_min = new_ds['wavelength'].min().item()
wavelength_max = new_ds['wavelength'].max().item()
# Range of time
time_min = new_ds['time'].min().item()
time_max = new_ds['time'].max().item()
print(f"Absorbance: min = {absorbance_min}, max = {absorbance_max}")
print(f"Wavelength: min = {wavelength_min}, max = {wavelength_max}")
print(f"Time: min = {time_min}, max = {time_max}")
Absorbance: min = 0.000108908769855, max = 0.9993752590009782
Wavelength: min = 350.0, max = 700.0
Time: min = 0.0, max = 300.0
Plot Spectra at given time#
import matplotlib.pyplot as plt
# Specify the time for which to plot the spectrum
time_point = 10.0 # Replace with your desired time value
# Select the data at the specified time
spectrum = new_ds.sel(time=time_point, method='nearest')
# Plot the spectrum
plt.figure(figsize=(10, 6))
plt.plot(spectrum['wavelength'], spectrum['absorbance'], label=f'Time = {time_point}')
plt.xlabel('Wavelength')
plt.ylabel('Absorbance')
plt.title(f'Spectrum at Time = {time_point}')
plt.legend()
plt.grid(True)
plt.show()
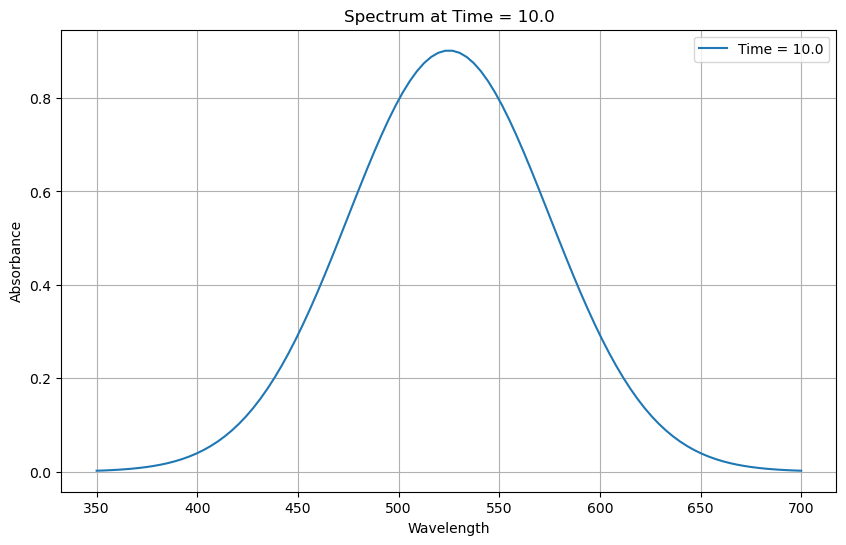
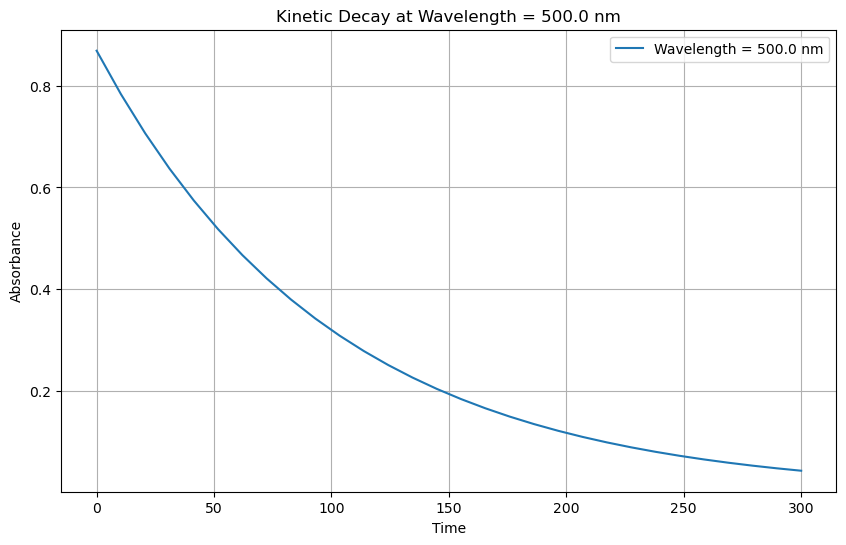
Plot Kinetic decay at wavelength#
# Specify the wavelength for which to plot the kinetic decay
wavelength_point = 500.0 # Replace with your desired wavelength value
# Select the data at the specified wavelength
kinetic_decay = new_ds.sel(wavelength=wavelength_point, method='nearest')
# Plot the kinetic decay
plt.figure(figsize=(10, 6))
plt.plot(kinetic_decay['time'], kinetic_decay['absorbance'], label=f'Wavelength = {wavelength_point} nm')
plt.xlabel('Time')
plt.ylabel('Absorbance')
plt.title(f'Kinetic Decay at Wavelength = {wavelength_point} nm')
plt.legend()
plt.grid(True)
plt.show()
Acknowledgements#
This content was developed with assistance from Perplexity AI and Chat GPT. Multiple queries were made during the Fall 2024 and the Spring 2025.